
計算機視覺目前已經被應用到多個領域,如無人駕駛、人臉識別、文字識別、智慧交通、VA/AR、以圖搜索、醫學圖像分析等等,是人工智能(AI)目前最火的領域之一。那計算機視覺是什么?完整鏈路是怎樣的?有哪些技術點?本文將跟大家一起探討。

計算機視覺(Computer Vision),就是用機器來模擬人的視覺獲取和處理信息的能力。它主要研究的內容是通過對圖片或視頻的處理,以獲得相應場景的三維信息,另外其研究很大程度上是針對圖像的內容。
本文主要參考了商湯科技CEO徐立老師的分享,將計算機視覺分為三部分:成像、早期視覺和識別理解。本文也是圍繞這三部分進行討論。
一、成像(Image)
成像就是計算機“看”的能力,是計算機視覺的輸入,相當于人的眼睛。影響計算機成像(看),主要有幾個因素:光、物體不全、模糊。
當然計算機看到的東西可能不僅只是人眼看到的那樣,甚至可以是人眼能力的延伸。
這個怎么說呢?后面將為會你解密。
1.1 光
(1)光線不足
光線不足是常見的問題之一,特別是在晚上。

比如說以上左圖可能是人眼看到的,但是通過對圖像做增強或者其他算法的處理,就可以變成了像以上右圖那樣,能看清物體了。這就是我們前面說的,機器成像也可以是人眼能力的延伸。
(2)曝光過渡
曝光過渡也比較容易出現在晚上,為什么呢?比如說你所拍攝的物體被車燈或其他強燈光照射,就容易出現曝光。

曝光的話,也可以通過一些簡單的算法處理,來還原圖像的樣子。
1.2 物體不全
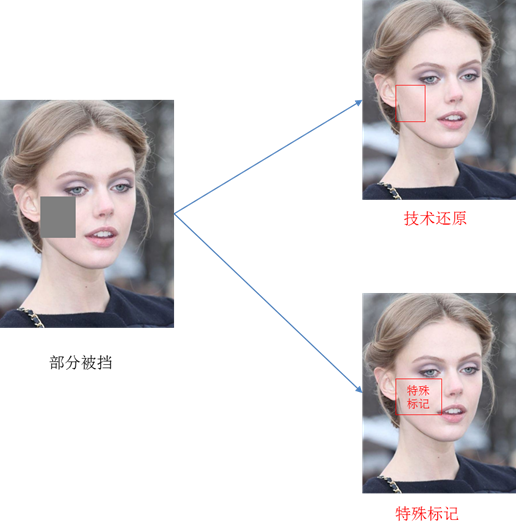
物體不全,主要表現有兩方面原因:被拍物體部分被遮擋住了、只拍了被拍物體的一部分。

那出現這種場景的時候,我們機器需要怎么處理呢?可以嘗試考慮的方向有兩點:
- 機器能不能根據拍得清晰的那部分的特征,自動去補全被遮擋的部分呢。
- 機器能不能對被擋住的部分做一些特殊的標記,傳送到下一層的時候,下一層就知道這個地方是異常的,需要特殊考慮。這樣就可以避免擋住的部分給下一層的傳達錯誤的信息。
1.3 模糊
造成模糊的原因可能有幾種:
- 運動模糊
- 對焦模糊
- 分辨率低(圖片質量差)
- 待識別物體過小
- 霧霾、煙氣等因素
那出現模糊的情況,計算機能做什么呢?
比如說拍照的時候,手一抖,就拍成了如下左圖,是可以通過一些算法,恢復成如下右圖的樣子。

或者說霧霾很嚴重的時候,拍出來的照片如下左圖,經過機器成像后,可以變成如下右圖的樣子,把圖片還原成了沒有霧霾的樣子。

那是不是一定要還原成物體最真實的樣子呢?也不見得,我們還可以做一些更加有情懷,更加有藝術感的處理。比如說把霧霾的圖片,變成油畫的樣子,就相當于給我們戴上了墨鏡,或者說戴上了3D眼睛去看電影。

所以,具體需要“看”成什么樣,也是根據我們的最終目的調整的。
二、早期視覺(Early Vision)
在徐立老師的定義里,早期視覺可以理解為視覺系統處理的中間結果,相當于我們人視覺感知系統的某一層。
就像我們的視覺感知系統那樣,雖然我們不太容易直觀的描述它做了什么處理,但它確實是有處理了一些信息,然后傳給了大腦的其系統。早期視覺也是這樣,充當一個中轉站的角色。
早期視覺主要包括的內容有:圖像分割、邊緣檢測、運動和深度估計等。
下面我們給大家介紹下圖像分割和邊緣檢測(運動和深度估計不太懂就不在這瞎bb了,感興趣的同學可以自行研究)。
2.1 圖像分割
圖像分割指的是根據灰度、 顏色、 紋理和形狀等特征把圖像劃分成若干互不交迭的區域, 并使這些特征在同一區域內呈現出相似性,而在不同區域間呈現出明顯的差異性。

比如說上圖,根據顏色區分出了不同的模塊,路是路,車是車,樹是樹。
圖像分割經典方法有:邊緣法和閾值法,但也可以用深度學習處理出很好的效果。
圖像分割在圖像處理中非常經典,也經常用到。比如說摳圖,首先進行圖像分割,取出我們目標部分,就可以把背景去掉了,最后還原。

還有表情包的合成:

2.2 邊緣檢測
邊緣檢測的目的就是找到圖像中亮度變化劇烈的像素點構成的集合,因此表現出來往往是事物的輪廓。

如果把“圖像分割”比喻成油畫的話,那“邊緣檢測”就是素描。
如果圖像中邊緣能夠精確的測量和定位,那么,就意味著實際的物體能夠被定位和測量,包括物體的面積、物體的直徑、物體的形狀等就能被測量。
以下4種情況會表現在圖像中時通常可以形成一個邊緣:
- 深度的不連續(物體處在不同的物平面上);
- 表面方向的不連續(如正方體的不同的兩個面);
- 物體材料不同(這樣會導致光的反射系數不同);
- 場景中光照不同(如被樹萌投向的地面)。
2.3 小結
早期視覺目前還有很多問題,還是不能做到很精準,因此現在端到端的訓練方法是個很好的解決方案,比如說我們用深度學習來做圖像分割。
三、識別理解(Recognition)
識別理解相當于人的大腦對信息的處理,經過處理后并給出反饋結果。
比如說人臉識別:

我們輸入一張人臉的圖片,機器就與人臉數據庫中人臉進行比對,然后機器就可以告訴你這個圖片的人是誰。
就像我們的大腦,看到一個人,我們就會去回憶,之前有沒有見過這個人,在哪里見過,他叫什么名字等等一些信息。
從這個例子中,我們可以看出,機器識別理解的兩個重要因素:
(1)數據庫(人的記憶)
只有你數據庫的數據足夠多,也就是說你見過足夠多的人,再給你看一個人的時候,你才知道這個人是誰。
(1)標簽(特征點)
你是根據什么辨識這個人的,他的膚色、發型、眼睛、鼻子、嘴巴等等,也就是說我們需要給這些數據打上足夠多的標簽,識別的時候,就可以拿這些標簽特征進行對比了。
徐立說:只要把圖片和這種標簽定義得足夠好,數據量足夠大,數據夠完善的話,它有非常大的可能在垂直領域上,能夠超越現有人類的識別準確率。
小結:
其實我們現在缺的不是數據,想要數據很簡單,裝足夠多的攝像頭,沒日沒夜的拍,數據就夠多了。但是這些數據意義不大,沒有標簽,或者說場景不夠豐富,因此我們缺乏的是高質量的數據,高質量表現在標簽足夠豐富和完善。
此文章主要參考了徐立老師的演講內容,感興趣可以去看下,徐立老師講得更加哲學和情懷。
附參考文章:
- 《商湯徐立:計算機視覺的完整鏈條,從成像到早期視覺再到識別理解》
- 《看AI產品經理如何介紹“計算機視覺”(基于實戰經驗和案例)》_Jasmine
- 《從0開始搭建產品經理的AI知識框架:計算機視覺》_藍風GO
- 《邊緣檢測》_Ronny
- 《閑聊圖像分割這件事兒》_言有三
- 《圖像分割》_古路
本文由 @Jimmy 原創發布于人人都是產品經理。未經許可,禁止轉載。
題圖來自Unsplash,基于CC0協議。
給作者打賞,鼓勵TA抓緊創作!
2人打賞